Crawlability is the foundation of your technical SEO strategy. Search bots will crawl your pages to gather information about your site.
If these bots are somehow blocked from crawling, they can’t index or rank your pages. The first step to implementing technical SEO is to ensure that all of your important pages are accessible and easy to navigate.
Below we'll cover some items to add to your checklist as well as some website elements to audit to ensure that your pages are prime for crawling.
1. Create an XML sitemap.
Remember that site structure we went over? That belongs in something called an XML Sitemap that helps search bots understand and crawl your web pages. You can think of it as a map for your website. You’ll submit your sitemap to Google Search Console and Bing Webmaster Tools once it’s complete. Remember to keep your sitemap up-to-date as you add and remove web pages.
2. Maximize your crawl budget.
Your crawl budget refers to the pages and resources on your site search bots will crawl.
Because crawl budget isn’t infinite, make sure you’re prioritizing your most important pages for crawling.
Here are a few tips to ensure that you’re maximizing your crawl budget:
- Remove or canonicalize duplicate pages.
- Fix or redirect any broken links.
- Make sure your CSS and Javascript files are crawlable.
- Check your crawl stats regularly and watch for sudden dips or increases.
- Make sure any bot or page you’ve disallowed from crawling is meant to be blocked.
- Keep your sitemap updated and submit it to the appropriate webmaster tools.
- Prune your site of unnecessary or outdated content.
- Watch out for dynamically generated URLs, which can make the number of pages on your site skyrocket.
3. Optimize your site architecture.
Your website has multiple pages. Those pages need to be organized in a way that allows search engines to easily find and crawl them. That’s where your site structure — often referred to as your website’s information architecture — comes in.
In the same way that a building is based on architectural design, your site architecture is how you organize the pages on your site.
Related pages are grouped together; for example, your blog homepage links to individual blog posts, which each link to their respective author pages. This structure helps search bots understand the relationship between your pages.
Your site architecture should also shape, and be shaped by, the importance of individual pages. The closer Page A is to your homepage, the more pages link to Page A, and the more link equity those pages have, the more importance search engines will give to Page A.
For example, a link from your homepage to Page A demonstrates more significance than a link from a blog post. The more links to Page A, the more “significant” that page becomes to search engines.
Conceptually, a site architecture could look something like this, where the About, Product, News, etc. pages are positioned at the top of the hierarchy of page importance.
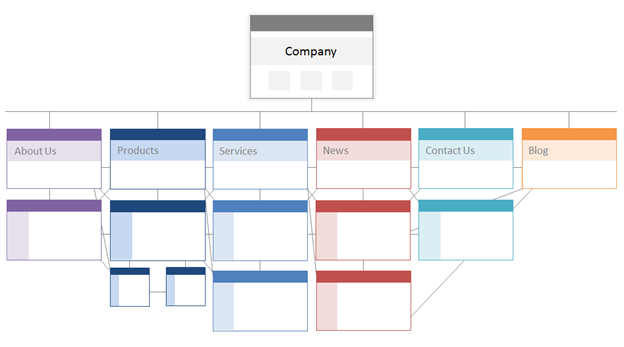
Make sure the most important pages to your business are at the top of the hierarchy with the greatest number of (relevant!) internal links.
4. Set a URL structure.
URL structure refers to how you structure your URLs, which could be determined by your site architecture. I’ll explain the connection in a moment. First, let’s clarify that URLs can have subdirectories, like blog.hubspot.com, and/or subfolders, like hubspot.com/blog, that indicate where the URL leads.
As an example, a blog post titled How to Groom Your Dog would fall under a blog subdomain or subdirectory. The URL might be www.bestdogcare.com/blog/how-to-groom-your-dog. Whereas a product page on that same site would be www.bestdogcare.com/products/grooming-brush.
Whether you use subdomains or subdirectories or “products” versus “store” in your URL is entirely up to you. The beauty of creating your own website is that you can create the rules. What’s important is that those rules follow a unified structure, meaning that you shouldn’t switch between blog.yourwebsite.com and yourwebsite.com/blogs on different pages. Create a roadmap, apply it to your URL naming structure, and stick to it.
Here are a few more tips about how to write your URLs:
- Use lowercase characters.
- Use dashes to separate words.
- Make them short and descriptive.
- Avoid using unnecessary characters or words (including prepositions).
- Include your target keywords.
Once you have your URL structure buttoned up, you’ll submit a list of URLs of your important pages to search engines in the form of an XML sitemap. Doing so gives search bots additional context about your site so they don’t have to figure it out as they crawl.
5. Utilize robots.txt.
When a web robot crawls your site, it will first check the /robot.txt, otherwise known as the Robot Exclusion Protocol. This protocol can allow or disallow specific web robots to crawl your site, including specific sections or even pages of your site. If you’d like to prevent bots from indexing your site, you’ll use a noindex robots meta tag. Let’s discuss both of these scenarios.
You may want to block certain bots from crawling your site altogether. Unfortunately, there are some bots out there with malicious intent — bots that will scrape your content or spam your community forums. If you notice this bad behavior, you’ll use your robot.txt to prevent them from entering your website. In this scenario, you can think of robot.txt as your force field from bad bots on the internet.
Regarding indexing, search bots crawl your site to gather clues and find keywords so they can match your web pages with relevant search queries. But, as we’ll discuss later, you have a crawl budget that you don’t want to spend on unnecessary data. So, you may want to exclude pages that don’t help search bots understand what your website is about, for example, a Thank You page from an offer or a login page.
No matter what, your robot.txt protocol will be unique depending on what you’d like to accomplish.
6. Add breadcrumb menus.
Remember the old fable Hansel and Gretel where two children dropped breadcrumbs on the ground to find their way back home? Well, they were on to something.
Breadcrumbs are exactly what they sound like — a trail that guides users to back to the start of their journey on your website. It’s a menu of pages that tells users how their current page relates to the rest of the site.
And they aren’t just for website visitors; search bots use them, too. 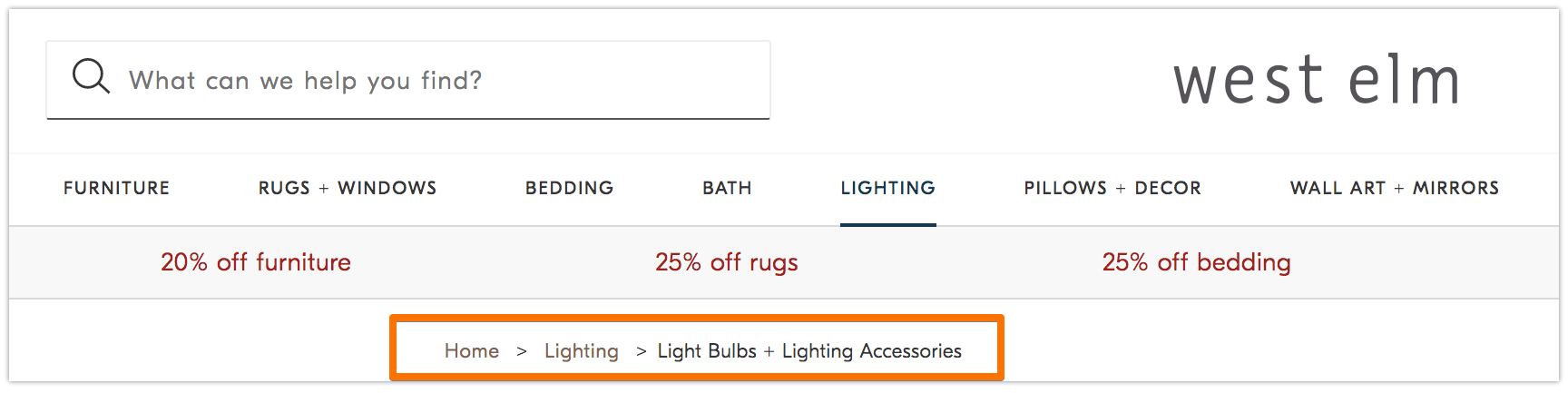
Breadcrumbs should be two things: 1) visible to users so they can easily navigate your web pages without using the Back button, and 2) have structured markup language to give accurate context to search bots that are crawling your site.
Not sure how to add structured data to your breadcrumbs? Use this guide for BreadcrumbList.
7. Use pagination.
Remember when teachers would require you to number the pages on your research paper? That’s called pagination. In the world of technical SEO, pagination has a slightly different role but you can still think of it as a form of organization.
Pagination uses code to tell search engines when pages with distinct URLs are related to each other. For instance, you may have a content series that you break up into chapters or multiple webpages. If you want to make it easy for search bots to discover and crawl these pages, then you’ll use pagination.
The way it works is pretty simple. You’ll go to the <head> of page one of the series and use
rel=”next” to tell the search bot which page to crawl second. Then, on page two, you’ll use rel=”prev” to indicate the prior page and rel=”next” to indicate the subsequent page, and so on.
It looks like this…
On page one:
On page two:
Note that pagination is useful for crawl discovery, but is no longer supported by Google to batch index pages as it once was.
8. Check your SEO log files.
You can think of log files like a journal entry. Web servers (the journaler) record and store log data about every action they take on your site in log files (the journal). The data recorded includes the time and date of the request, the content requested, and the requesting IP address. You can also identify the user agent, which is a uniquely identifiable software (like a search bot, for example) that fulfills the request for a user.
But what does this have to do with SEO?
Well, search bots leave a trail in the form of log files when they crawl your site. You can determine if, when, and what was crawled by checking the log files and filtering by the user agent and search engine.
This information is useful to you because you can determine how your crawl budget is spent and which barriers to indexing or access a bot is experiencing. To access your log files, you can either ask a developer or use a log file analyzer, like Screaming Frog.
Just because a search bot can crawl your site doesn’t necessarily mean that it can index all of your pages. Let’s take a look at the next layer of your technical SEO audit — indexability.
< Technical SEO Foundations Indexability Checklist >
No comments:
Post a Comment